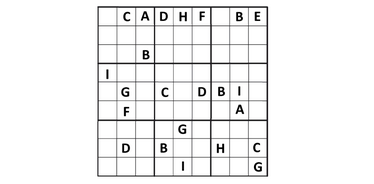
Ученые из Университета Колорадо (Anirudh Maiya, Razan Alghamdi, Maria Leonor Pacheco, Ashutosh Trivedi, Fabio Somenzi) протестировали LLM на головоломках 6×6 судоку. Новые исследования показали, что современные языковые модели умеют решать логические задачи, но пока не способны доступно объяснять свой ход мыслей:
- В исследовании использовали 2 293 уникальные головоломки.
- Проверили пять моделей: четыре открытые (Gemma, Mistral и две версии Llama) и одну закрытую от OpenAI (o1-preview).
- Задачи были разной сложности: от простых до «дьявольских».
Результаты:
- Открытые модели решили менее 1% задач, OpenAI справилась гораздо лучше – 65% правильных решений.
- Для простых головоломок (категории Easy и Medium) OpenAI показала 100% точность. Для самых сложных судоку («Diabolical») точность падала до 40%.
Границы возможностей ИИ
Авторы исследования посмотрели, как ИИ объясняет свои шаги. Для этого взяли 20 головоломок и дали экспертам оценить ответы по трем критериям:
- Обоснование. Только в 5% случаев модель смогла объяснить, почему выбрала то или иное число. В остальных ответах она ограничивалась перечислением правил судоку, которые не имели отношения к конкретной головоломке.
- Доступность изложения. Лишь 7,5% объяснений были ясными и последовательными, в остальных случаях сбивались на общие фразы, использовали противоречивую терминологию или просто перепрыгивали через шаги.
- Практическая польза. Всего 2,5% объяснений помогали понять стратегию решения судоку.
Почему одних ответов недостаточно
Сегодня ИИ все активнее применяется в медицине, бизнесе, праве. Но если модель не умеет прозрачно объяснять свои шаги, использовать ее в критически важных сферах становится опасно. Ведь для таких задач, как постановка диагноза или юридическое решение, объяснение порой важнее самого ответа. Ученые отмечают: чтобы модели стали по-настоящему полезными партнерами, их нужно научить не только находить правильный ответ, но и переводить сложные логические шаги в понятный человеку язык.
Исследование: https://arxiv.org/pdf/2505.15993