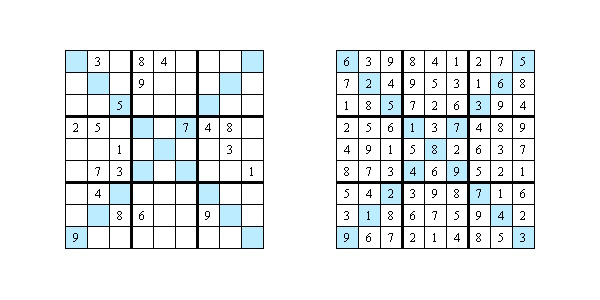
科羅拉多大學的研究人員(Anirudh Maiya, Razan Alghamdi, Maria Leonor Pacheco, Ashutosh Trivedi, Fabio Somenzi)在6×6 數獨謎題上測試了LLM。最新研究顯示,現代語言模型能夠解決邏輯問題,但仍無法清楚地解釋其推理過程:
- 研究中使用了2293個獨特的謎題。
- 測試了五個模型:四個開源模型(Gemma、Mistral和兩個版本的Llama)以及一個來自OpenAI的封閉模型(o1-preview)。
- 任務難度從簡單到「惡魔級」不等。
結果:
- 開源模型解決不到1%的謎題,而OpenAI表現更佳,正確率達65%。
- 對於簡單的謎題(Easy和Medium),OpenAI的準確率為100%。對於最困難的數獨(「Diabolical」),準確率下降到40%。
人工智慧能力的侷限
研究作者檢視了AI如何解釋其解題步驟。他們選擇了20個謎題,並請專家根據三個標準進行評估:
- 推理依據。只有5%的情況下,模型能解釋為何選擇某個數字。其餘情況只是列舉一些與該謎題無關的數獨規則。
- 表達清晰度。僅有7.5%的解釋清楚且連貫,其餘的模糊、矛盾或跳過步驟。
- 實際價值。僅2.5%的解釋有助於理解解數獨的策略。
為什麼答案本身不夠
如今,人工智慧越來越多地應用於醫學、商業和法律。如果模型不能透明地解釋其推理,在關鍵領域的使用將是危險的。在診斷或法律判決等任務中,解釋有時比答案本身更重要。研究人員指出,要讓模型成為真正有用的夥伴,就必須不僅能找到正確答案,還能將複雜的推理過程轉換為人類能理解的語言。