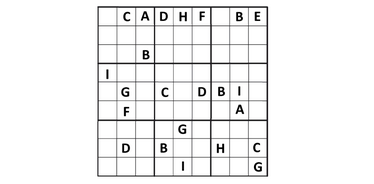
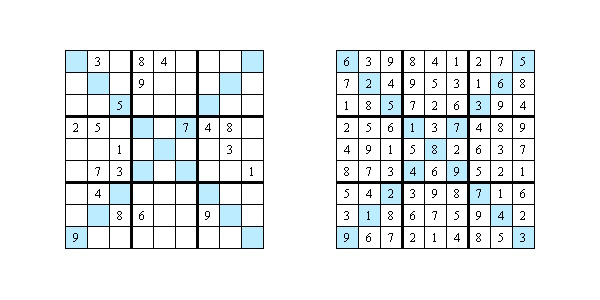
科罗拉多大学的研究人员(Anirudh Maiya, Razan Alghamdi, Maria Leonor Pacheco, Ashutosh Trivedi, Fabio Somenzi)在6×6 数独谜题上测试了LLM。最新研究表明,现代语言模型能够解决逻辑问题,但仍无法清晰地解释其推理过程:
- 研究中使用了2293个独特的谜题。
- 测试了五个模型:四个开源模型(Gemma、Mistral和两个版本的Llama)以及一个来自OpenAI的闭源模型(o1-preview)。
- 任务难度从简单到“地狱级”不等。
结果:
- 开源模型解决了不到1%的谜题,而OpenAI表现更好,正确率达65%。
- 对于简单的谜题(Easy和Medium),OpenAI的准确率为100%。对于最困难的数独(“Diabolical”),准确率下降到40%。
人工智能能力的局限
研究作者考察了AI如何解释其解题步骤。他们选择了20个谜题,并请专家根据三个标准进行评估:
- 推理依据。只有5%的情况下,模型能解释为何选择某个数字。其余情况只是罗列一些与该谜题无关的数独规则。
- 表达清晰度。仅有7.5%的解释清楚且连贯,其余的模糊、矛盾或跳过步骤。
- 实际价值。仅2.5%的解释有助于理解解数独的策略。
为什么答案本身不够
如今,人工智能越来越多地应用于医学、商业和法律。如果模型不能透明地解释其推理,在关键领域的使用将是危险的。在诊断或法律判决等任务中,解释有时比答案本身更重要。研究人员指出,要让模型成为真正有用的伙伴,就必须不仅能找到正确答案,还能将复杂的推理过程转化为人类能够理解的语言。